Premiers pas avec la programmation R
Published:
Introduction
R est un langage de programmation axé sur l'analyse statistique et graphique. Il est donc couramment utilisé dans l'inférence statistique, l'analyse des données et l'apprentissage automatique. R est actuellement l'un des langages de programmation les plus demandés sur le marché du travail en science des données (figure 1).
![Figure 1: Langages de programmation les plus demandés pour la science des données en 2019 [1]](https://cdn-images-1.medium.com/max/2000/1*lsI8O_2yGfYoUpCT6kNynw.png)
Figure 1: Langages de programmation les plus demandés pour la science des données en 2019 [1]
R est disponible pour être installé à partir de r-project.org et l'un des R environnement de développement intégré (IDE) le plus utilisé est certainement RStudio.
IL existe deux principaux types de packages (blibliothèques) qui peuvent être utilisés pour ajouter des fonctionnalité à R: les packages de base et les packages distribués. Les packages de base sont livrés avec l'installation de R, les packages distribués peuvent être téléchargés gratuitement à l'aide du CRAN.
Une fois R installé, nous pouvons commencer à faire quelques analyses de données.
Analyse des données
Dans cet exemple, je vais vous guider à travers une analyse de bout en bout de l'ensemble de données de classification des prix de téléphones mobiles disponible sur Kaggle pour prédire la fourchette de prix des téléphones mobiles. Le code que j'ai utilisé pour cette démonstration est disponible sur mon compte Github : Getting-Started-With-R-Programming.
Importation de bibliothèques
Tout d'abord, nous devons importer toutes les bibliothèques nécessaires.
Les packages peuvent être installés dans R à l'aide de la commande install.packages() puis chargés à l'aide de la commande library(). Dans ce cas, j'ai décidé d'installer d'abord PACMAN (Package Management Tool) puis de l'utiliser pour installer et charger tous les autres packages. PACMAN facilite le chargement de la bibliothèque car il peut installer et charger toutes les bibliothèques nécessaires dans une seule ligne de code.
.rs.restartR() # Restart Kernel Session
install.packages("pacman")
library(pacman)
pacman::p_load(pacman,dplyr, ggplot2, rio, gridExtra, scales, ggcorrplot, caret, e1071)
Les packages importés sont utilisés pour ajouter les fonctionnalités suivantes:
- dplyr: traitement et analyse des données.
- ggplot2: visualisation des données.
- rio: importation et exportation de données.
- gridExtra: pour créer des tracés d'objets graphiques auxquels vous pouvez librement disposer sur une page.
- scales: utilisées pour mettre à l'échelle les données dans les graphiques.
- ggcorrplot: est utilisé pour visualiser les matrices de corrélation en utilisant ggplot2 dans le backend.
- caret: est utilisé pour former et tracer des modèles de classification et de régression.
- e1071: contient des fonctions pour exécuter des algorithmes d'apprentissage automatique tels que les machines à vecteurs de support, Naive Bayes.
- etc.
Pré-traitement des données
Nous pouvons maintenant chargé notre jeu de données, afficher ses 5 premières colonnes (figure 2) et imprimer un résumé des principales caractéristiques de chaque entité (figure 3). Dans R, nous pouvons créer de nouveaux objets en utilisant l' opérateur <- .
# Loading our dataset
df <- import("./mobile_price.csv")
head(df)
summary(df)

Figure 2: header de l'ensemble de données
Quelques statistques que nous pouvons vérifier (toujours conseillé)
# Mise en place de statistiques descriptives, selon le type de variable.
# Dans le cas d'une variable numérique -> Donne la moyenne, la médiane, le mode, la plage et les quartiles.
# Dans le cas d'une variable de facteur -> Donne un tableau avec les fréquences.
# En cas de Facteur + Variables Numériques -> Donne le nombre de valeurs manquantes.
# En cas de variables de caractère -> Donne la longueur et la classe.
La fonction de résumé nous fournit une brève description statistique de chaque entité de notre ensemble de données. Selon la nature de la fonctionnalité considérée, différentes statistiques seront fournies:
- Caractéristiques numériques: moyenne, médiane, mode, plage et quartiles.
- Caractéristiques des facteurs: fréquences.
- Un mélange de facteurs et de fonctionnalités numériques: Nombre de valeurs manquantes.
- Caractéristiques des personnages: Durée de la classe.
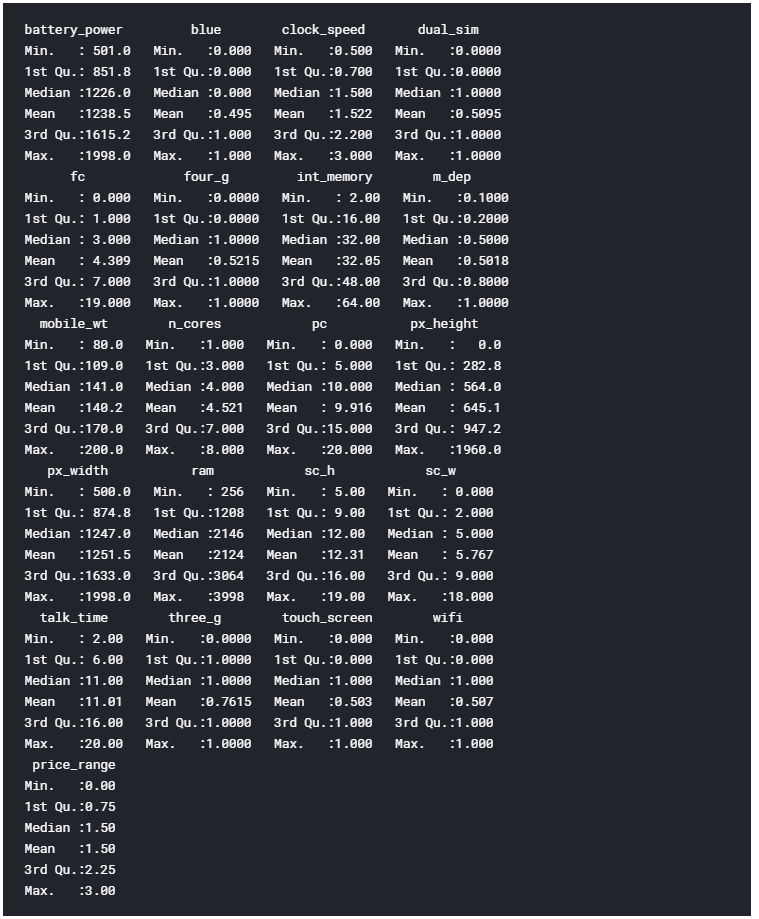
Figure 3: Résumé de l'ensemble de données
Enfin, nous pouvons maintenant vérifier si notre ensemble de données contient des valeurs manquantes (NaN) en utilisant le code ci-dessous.
# Checking for Missing values
missing_values <- df %>% summarize_all(funs(sum(is.na(.))/n()))
missing_values <- gather(missing_values, key="feature", value="missing_pct")
missing_values %>%
ggplot(aes(x=reorder(feature,-missing_pct),y=missing_pct)) +
geom_bar(stat="identity",fill="red")+
coord_flip()+theme_bw()Comme nous pouvons le voir sur la figure 4, aucune valeur manquante n'a été trouvé.
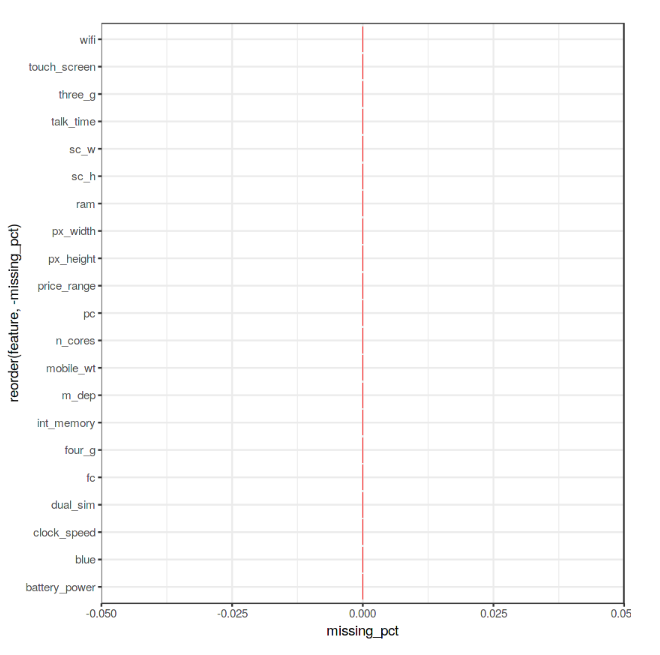
Figure 4: Pourcentage de NaN dans chaque variable
Visualisation de données
Nous pouvons maintenant commencer notre visualisation des données en traçant une matrice de corrélation de notre ensemble de données (figure 5).
corr <- round(cor(df), 8)
ggcorrplot(corr)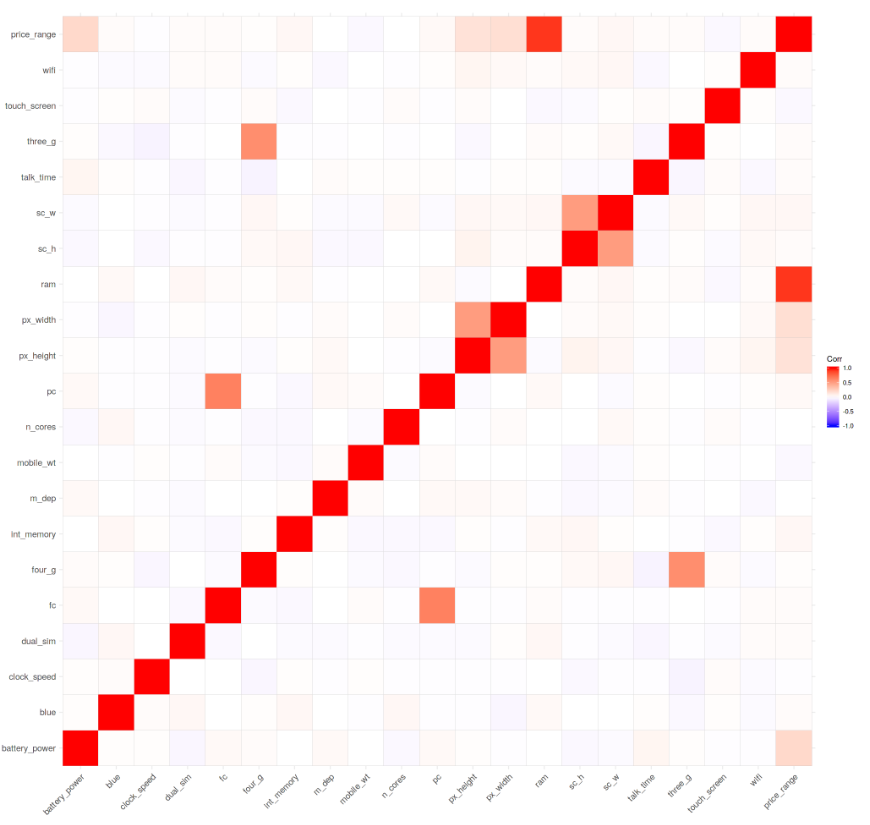
Figure 5: Matrice de corrélation
Par la suite, nous pouvons commencer à analyser les variables (entités) individuellement à l'aide des graphiques BarCharts et BoxPlots. Avant de créer ces tracés, nous devons d'abord convertir les entités considérées comme numérique en facteur (cela nous permet de regrouper nos données, puis de tracer les données regroupées).
df$blue <- as.factor(df$blue)
df$dual_sim <- as.factor(df$dual_sim)
df$four_g <- as.factor(df$four_g)
df$price_range <- as.factor(df$price_range)
Nous pouvons maintenant créer 3 diagrammes à barres en les stockant dans différentes variables (p1, p2, p3), puis les ajouter à grid.arrange() pour créer un sous-tracé. Dans ce cas, j'ai décidé d'examiner les fonctionnalités Bluetooth, Dual Sim et 4G.
# Bar Chart Subplots
p1 <- ggplot(df, aes(x=blue, fill=blue)) +
theme_bw() +
geom_bar() +
ylim(0, 1050) +
labs(title = "Bluetooth") +
scale_x_discrete(labels = c('Not Supported','Supported'))
p2 <- ggplot(df, aes(x=dual_sim, fill=dual_sim)) +
theme_bw() +
geom_bar() +
ylim(0, 1050) +
labs(title = "Dual Sim") +
scale_x_discrete(labels = c('Not Supported','Supported'))
p3 <- ggplot(df, aes(x=four_g, fill=four_g)) +
theme_bw() +
geom_bar() +
ylim(0, 1050) +
labs(title = "4 G") +
scale_x_discrete(labels = c('Not Supported','Supported'))
grid.arrange(p1, p2, p3, nrow = 1)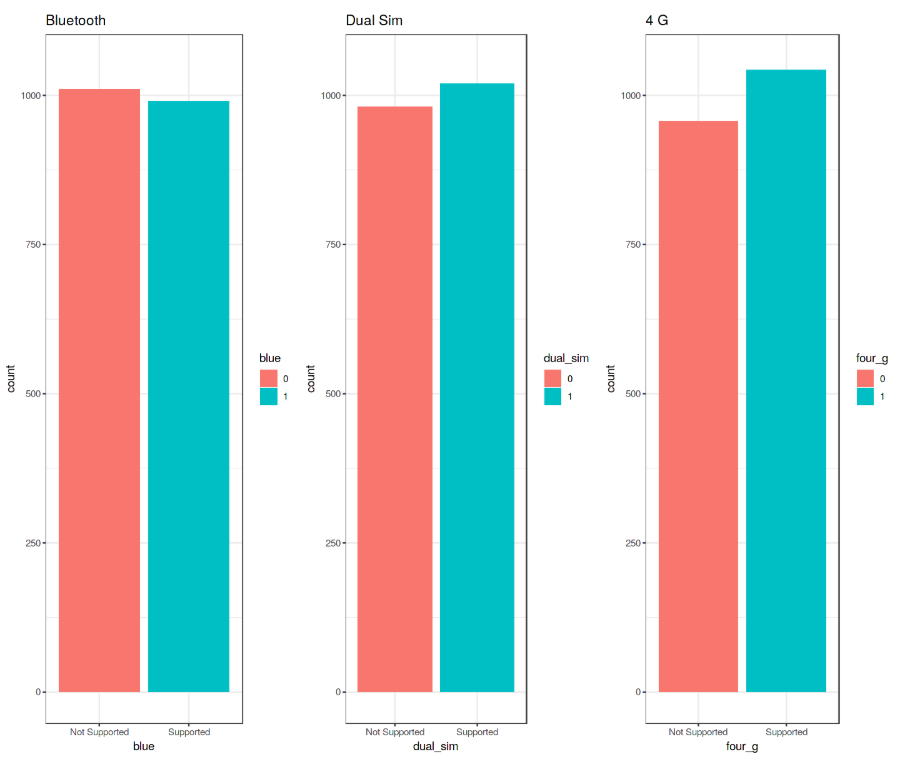 Figure 6: Analyse du diagramme à barres
Figure 6: Analyse du diagramme à barres
Ces tracés ont été créés à l'aide de la bibliothèque ggplot2 . Lors de l'appel de la fonction ggplot() , nous créons un système de coordonnées sur lequel nous pouvons ajouter des couches par-dessus [2].
Le premier argument que nous donnons à la fonction ggplot() est l'ensemble de données que nous allons utiliser et le second est plutôt une fonction esthétique dans laquelle nous définissons les variables que nous voulons tracer. Nous pouvons ensuite continuer d'ajouter d'autres arguments tels que nous définissant une fonction géométrique souhaitée (par exemple barplot, scatter, boxplot, histogram, etc…), en ajoutant un thème de tracé, des limites d'axe, des étiquettes, etc…
En poussant notre analyse un peu plus loin, nous pouvons maintenant calculer les pourcentages précis de la différence entre les différents cas en utilisant la fonction prop.table(). Comme nous pouvons le voir sur la sortie résultante (figure 7), 50,5% des appareils mobiles considérés ne prennent pas en charge Bluetooth, 50,9% est Dual Sim et 52,1% a 4G.
prop.table(table(df$blue)) # cell percentages
prop.table(table(df$dual_sim)) # cell percentages
prop.table(table(df$four_g)) # cell percentages
Figure 7: Pourcentage de distribution des classes
Nous pouvons maintenant continuer à créer 3 Box Plots différents en utilisant la même technique utilisée auparavant. Dans ce cas, j'ai décidé d'examiner comment le fait d'avoir plus de puissance de batterie, de poids de téléphone et de RAM (Random Access Memory) peut affecter les prix des mobiles. Dans cet ensemble de données, nous ne recevons pas les prix réels du téléphone, mais une fourchette de prix indiquant à quel point le prix est élevé (quatre niveaux différents de 0 à 3).
# Bar Chart Subplots
p1 <- ggplot(df, aes(x=price_range, y = battery_power, color=price_range)) +
geom_boxplot(outlier.colour="red", outlier.shape=8,
outlier.size=4) +
labs(title = "Battery Power vs Price Range")
p2 <- ggplot(df, aes(x=price_range, y = mobile_wt, color=price_range)) +
geom_boxplot(outlier.colour="red", outlier.shape=8,
outlier.size=4) +
labs(title = "Phone Weight vs Price Range")
p3 <- ggplot(df, aes(x=price_range, y = ram, color=price_range)) +
geom_boxplot(outlier.colour="red", outlier.shape=8,
outlier.size=4) +
labs(title = "RAM vs Price Range")
grid.arrange(p1, p2, p3, nrow = 1)
Les résultats sont résumés dans la figure 8. L'augmentation de la puissance de la batterie et de la RAM entraîne systématiquement une augmentation du prix. Au lieu de cela, les téléphones plus chers semblent globalement plus légers. Dans le graphique RAM vs Price Range, des valeurs aberrantes ont été enregistrées dans la distribution globale.
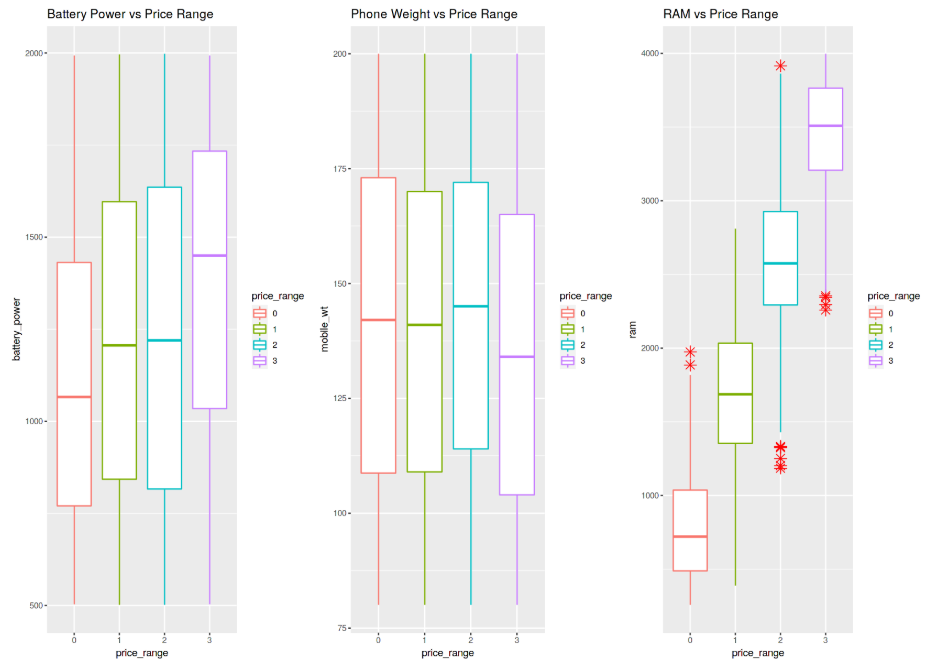
Figure 8: Analyse du diagramme en boîte
Enfin, nous allons maintenant examiner la distribution de la qualité de la caméra en mégapixels pour les caméras frontale et primaire (figure 9). Fait intéressant, la distribution de la caméra avant semble suivre une distribution en décroissance exponentielle tandis que la caméra principale suit à peu près une distribution uniforme.
data = data.frame(MagaPixels = c(df$fc, df$pc), Camera = rep(c("Front Camera", "Primary Camera"), c(length(df$fc), length(df$pc))))
ggplot(data, aes(MagaPixels, fill = Camera)) + geom_bar(position = 'identity', alpha = .5)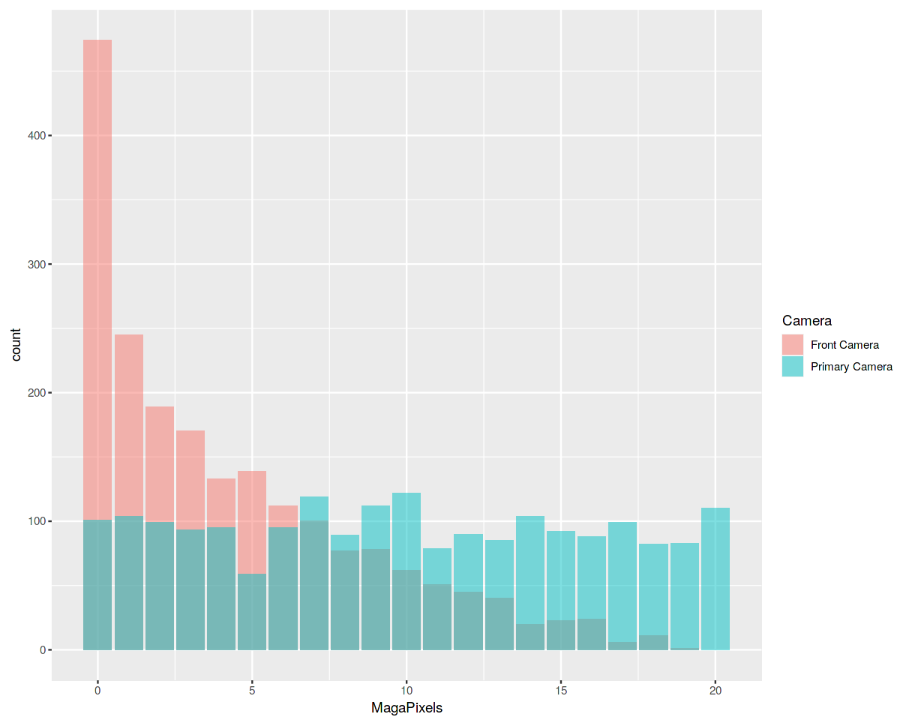
Figure 9: Analyse d'histogramme
Apprentissage automatique
Afin d'effectuer notre analyse d'apprentissage automatique, nous devons d'abord convertir nos variables de facteur sous forme numérique, puis diviser notre ensemble de données en trains et ensembles de tests (ratios 75:25). Et ensuite nous séparons les données de fonctionnalités aux données d'étiquettes.
df$blue <- as.numeric(df$blue)
df$dual_sim <- as.numeric(df$dual_sim)
df$four_g <- as.numeric(df$four_g)
df$price_range <- as.numeric(df$price_range)## 75% of the sample size
smp_size <- floor(0.75 * nrow(df))# set the seed to make our partition reproducible
set.seed(123)
train_ind <- sample(seq_len(nrow(df)), size = smp_size)train <- df[train_ind, ]
test <- df[-train_ind, ]x_train <- subset(train, select = -price_range)
y_train <- train$price_range
x_test <- subset(test, select = -price_range)
y_test <- test$price_range
Il est maintenant temps de former notre modèle d'apprentissage automatique. Dans cet exemple, j'ai décidé d'utiliser les machines à vecteurs de support (SVM) comme classificateur multiclasse. En utilisant R summary (), nous pouvons ensuite inspecter les paramètres de notre modèle formé (figure 10).
model <- svm(x_train, y_train, type = 'C-classification',
kernel = 'linear') print(model)
summary(model)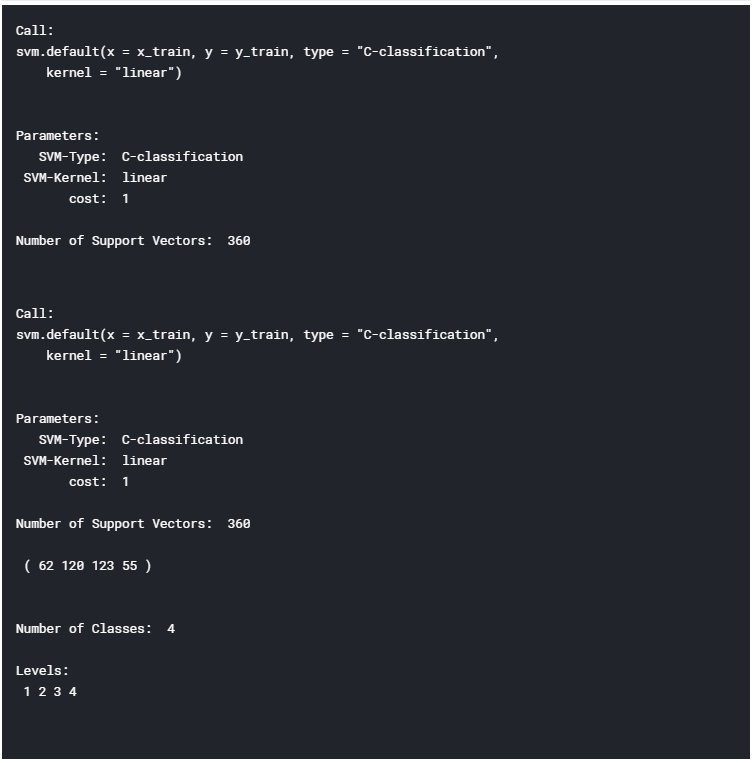
Figure 10: Résumé du modèle d'apprentissage automatique
Enfin, nous pouvons maintenant tester notre modèle en faisant des prédictions sur l'ensemble des données de test. En utilisant la fonction R confusionMatrix() , nous pouvons alors obtenir un rapport complet de la précision de notre modèle (figure 11). Dans ce cas, une précision de 96,6% a été enregistrée.
# testing our model
pred <- predict(model, x_test)pred <- as.factor(pred)
y_test <- as.factor(y_test)
confusionMatrix(y_test, pred)

Figure 11: Modèle de rapport d'exactitude
Conclusion
C'est la fin de l'initiation à la programmation en R. J'espère que cet article vous a plu, merci d'avoir lu!
Bibliographie
[1] Which languages are important for Data Scientists in 2019? Quora. Consulté sur: https://www.quora.com/Which-languages-are-important-for-Data-Scientists-in-2019
[2] R for Data Science, Garrett Grolemund and Hadley Wickham. Consulté sur: https://www.bioinform.io/site/wp-content/uploads/2018/09/RDataScience.pdf
