Analyse et prévision des ventes du Black Friday
Published:
L’ojectif de ce projet est de faire une EDA et une prévision d’achat pour les données de ventes du Black Friday avec le language Python.
Dans cette analyse, nous allons faire deux choses. Tout d’abord, explorerer les données et trouver des corrélations entre différents éléments, afin de pouvoir obtenir des informations sur les futures stratégies marketing. En plus de cela, utiliser également la méthode de régression pour prédire les achats futurs. L’ensemble de données utilisé dans cette analyse contient des informations sur les transactions dans un magasin le Black Friday, y compris les caractéristiques démographiques des clients et les détails des transactions. L’ensemble de données provient d’un concours hébergé par Analytics Vidhya.
Importation des library
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.ensemble import RandomForestRegressor
from sklearn import preprocessing
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import cross_val_score
%matplotlib inline
import warnings
warnings.filterwarnings("ignore")
C:\Users\Soubeiga Armel\Documents\WPy64-3740\python-3.7.4.amd64\lib\site-packages\statsmodels\tools\_testing.py:19: FutureWarning: pandas.util.testing is deprecated. Use the functions in the public API at pandas.testing instead.
import pandas.util.testing as tm
Importation des données
Nous lisons les données grâce à la fonction read_csv de la library pandans as pd. La fonction info permet d’avoir toutes les information sur la base de données importée.
data = pd.read_csv("https://raw.githubusercontent.com/armelsoubeiga/sales_prediction_Machine_Learning/master/Projet_2/BlackFriday.csv")
print(data.info())
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 537577 entries, 0 to 537576
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 User_ID 537577 non-null int64
1 Product_ID 537577 non-null object
2 Gender 537577 non-null object
3 Age 537577 non-null object
4 Occupation 537577 non-null int64
5 City_Category 537577 non-null object
6 Stay_In_Current_City_Years 537577 non-null object
7 Marital_Status 537577 non-null int64
8 Product_Category_1 537577 non-null int64
9 Product_Category_2 370591 non-null float64
10 Product_Category_3 164278 non-null float64
11 Purchase 537577 non-null int64
dtypes: float64(2), int64(5), object(5)
memory usage: 49.2+ MB
None
Nous allons visualiser les cinq (5) première lignes de la base de données. Nous pouvons également visuliser les 5 dernières lignes en faisant data.tail(5)
data.head(5)
Ci-dessus nous allons visuliser les valeurs manquantes, dans la bases de données. Nous voyons qu’il y’a des variables dont la réponse est True. Cela signifie que ces variables contiennent des valeurs manquantes.
print("Missing values:\n\n\n", data.isnull().any(), "\n")
Missing values:
User_ID False
Product_ID False
Gender False
Age False
Occupation False
City_Category False
Stay_In_Current_City_Years False
Marital_Status False
Product_Category_1 False
Product_Category_2 True
Product_Category_3 True
Purchase False
dtype: bool
On dirait que certains clients ont plusieurs entrées pour eux, essayons de combiner ces entrées en une seule entrée, afin que nous puissions obtenir des caractéristiques démographiques plus précises, mais nous utiliserons toujours les données d’origine pour des considérations d’achat.
Nous allons remplacer les nan par 0, ce qui signifie qu’ils ont acheté un article de ces catégories
# remplissez nan avec 0, ce qui signifie qu'ils ont acheté un article de ces catégories
data = data.fillna(0)
data_numeric = data[["User_ID", "Product_Category_1", "Product_Category_2", "Product_Category_3", "Purchase"]].groupby("User_ID").sum().reset_index().drop("User_ID", axis=1)
data_categoric = data.drop_duplicates("User_ID")[["User_ID", "Gender", "Age", "Occupation","City_Category", "Stay_In_Current_City_Years", "Marital_Status"]].reset_index().drop(["index"], axis=1)
data = pd.concat([data_categoric, data_numeric], axis=1)
data[["Product_Category_2", "Product_Category_3"]] = data[["Product_Category_2", "Product_Category_3"]].astype("int64")
print("\nNombre de clients le Black Friday: ", data.shape[0])
Nombre de clients le Black Friday: 5891
Sur les 537577 observations de la base, nous totalisons 5891 clients uniques.
Analyse Exploratoire
1. Gender et age
data["Gender"].value_counts().plot.pie(title="Sexe du client", explode=(0.1, 0), labels=["Masculin", "Feminin"], autopct="%1.1f%%", shadow=True)
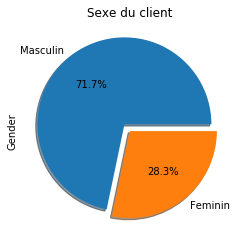
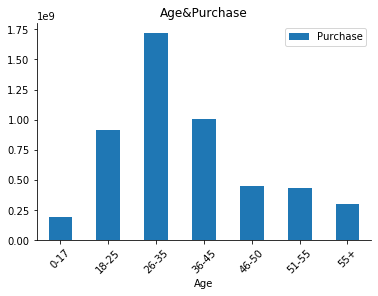
Nous avons plus d’hommes que de femmes dans la base de données. 71,7% d’homme contre 28,3% de femme. En regardans ci-dessous, l’histogramme de la variable classe d’âge en fonction du montant dépensé, nous observons que la tranche d’âge de [26-25] ans sont ceux qui dépensent plus. Et les enfants de 0-17 ans dépensent moins.
data.groupby(["Age"]).sum()[["Purchase"]].plot.bar(title="Age&Purchase")
plt.xticks(rotation=45)
sns.despine()
2. Bivarié - Sexe et age
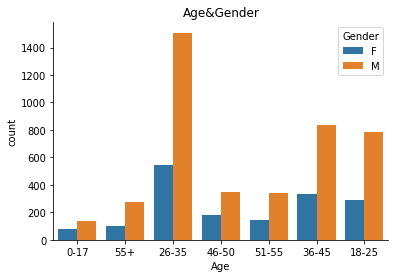
sns.countplot(data["Age"], hue=data["Gender"]).set_title("Age&Gender")
sns.despine()
x = data.groupby(["Gender"]).mean()[["Purchase"]].index
y = data.groupby(["Gender"]).mean()[["Purchase"]].values
plt.plot(x, y,"ro")
plt.xticks(x, ["Masculin", "Feminin"])
plt.title("Montant moyen en fonction du sexe")
sns.despine()

3. Interpretation
À partir des chiffres d’âge et de sexe, nous pouvons voir plusieurs choses intéressantes.
Tout d’abord, les principaux clients de la vente du Black Friday sont des hommes (plus de 70%), en particulier ceux âgés de 26 à 35 ans.
Deuxièmement, le graphique du montant d’achat moyen en fonction du sexe, montre que les femmes dépensent généralement plus (environ 30 000 $ de plus) que les hommes.
En fin, on peut voir aussi que tout sexe confondu, les clients de 18 à 45 ans représentent près des quatre cinquièmes (4 milliards) des ventes du Black Friday. Les jeunes hommes ont montré un pouvoir d’achat globalement plus élevé, mais il est également possible que les clients masculins paient lorsqu’ils font des achats avec des femmes.
4. city
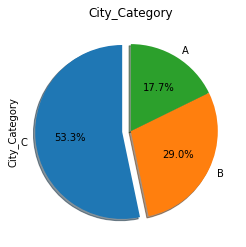
data["City_Category"].value_counts().plot.pie(title="City_Category", startangle=90, explode=(0.1, 0, 0), autopct="%1.1f%%", shadow=True)
5. City en fonction du montant (Purchase)
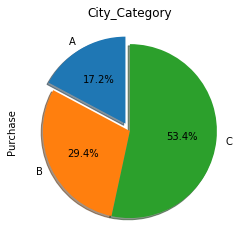
data.groupby("City_Category")["Purchase"].sum().plot.pie(title="City_Category", startangle=90, explode=(0.1, 0, 0), autopct="%1.1f%%", shadow=True)
# data.groupby(["City_Category"]).mean()[["Purchase"]].plot.bar(title="Mean purchase of different city", figsize=(9, 6))
# sns.despine()
x = data.groupby(["City_Category"]).mean()[["Purchase"]].index
y = data.groupby(["City_Category"]).mean()[["Purchase"]].values
plt.plot(x, y,"ro")
plt.title("Mean purchase of different city categories")
sns.despine()

6. Interpretatiion
Les clients du city C représentent plus de la moitié de nos ventes du Black Friday. Étonnamment, bien qu’il n’y ait pas beaucoup de clients de la ville B, ils dépensent environ 45 000 $ de plus que les autres clients. Au contraire, nous n’avons pas eu beaucoup de clients de la ville A et ils ont dépensé le moins. Cela doit être noté lors de l’élaboration de futurs plans de marketing.
7. Occupation
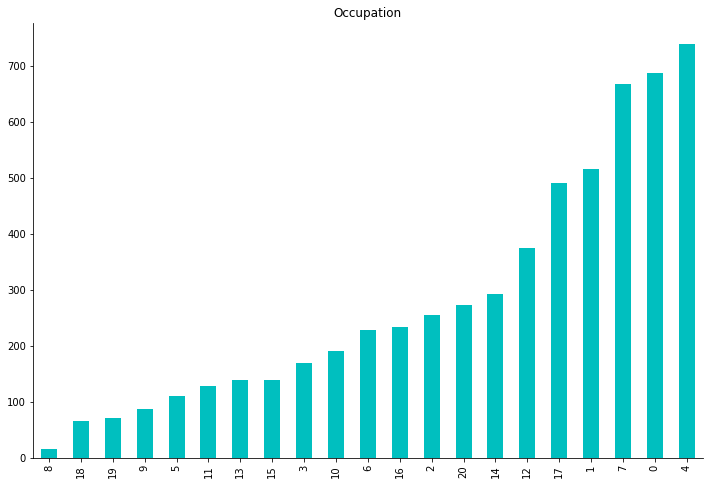
data["Occupation"].value_counts().sort_values().plot.bar(title="Occupation", color="c", figsize=(12, 8))
sns.despine()
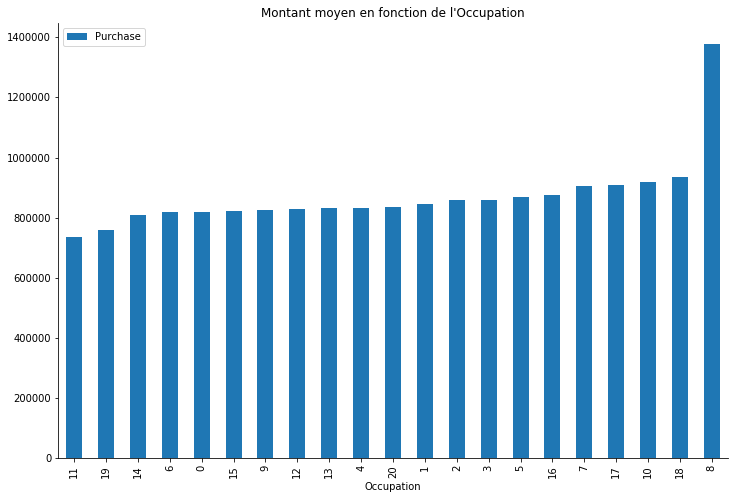
data.groupby(["Occupation"]).mean()[["Purchase"]].sort_values(by="Purchase").plot.bar(title="Montant moyen en fonction de l'Occupation", figsize=(12, 8))
sns.despine()
8. Interpretation
Selon l’occupation seulement, nous voyons que nos clients ont un large éventail de professions. Les ocupations 4, 0, 7, 1, 17, 1 sont les plus courantes et dépassent de loin les autres professions, ce qui signifie que les personnes ayant ces six professions devraient certainement être notre principale cible marketing.
La deuxième figure ci-dessus montre quelque chose de très différent. La plupart des gens ont dépensé environ 600K à 800K dans le magasin. Les personnes occupant les professions 18, 19 dépensent généralement plus que les autres malgrés que ça soit les professions moins répresentés.
9. Stabilité de la résidence
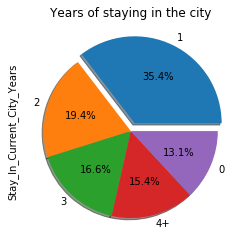
data["Stay_In_Current_City_Years"].value_counts().plot.pie(title="Years of staying in the city", explode=(0.1, 0, 0, 0, 0), autopct="%1.1f%%", shadow=True)
data.groupby(["Stay_In_Current_City_Years"]).mean()[["Purchase"]].sort_values(by="Purchase").plot.bar(title="Montant moyen en fonction des diffrentes stabilités", color="orange")
sns.despine()
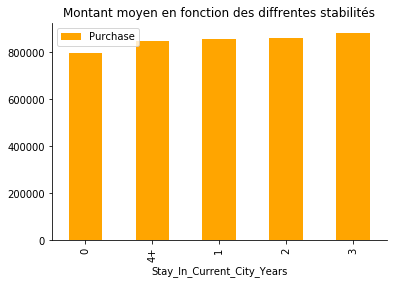
10. Interpretation
On observe que les nouveaux résidents (un an ou moins : 0+1 ans) représentent environ la moitié de nos clients du Black Friday.
Mais les gens qui vivent dans la zone plus longtemps dépensent un peu plus que les nouveaux arrivants. Puisqu’ils ont choisi de rester avec nous, nous devons découvrir ce qui les a maintenus fidèles afin que nous puissions faire de meilleurs plans pour garder plus de clients au lieu de les perdre au fil du temps.
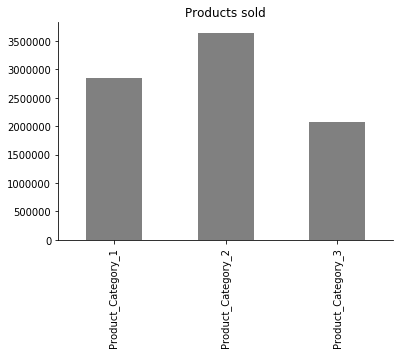
11. Les produits
data.sum()[["Product_Category_1", "Product_Category_2", "Product_Category_3"]].plot.bar(title="Products sold", color="grey")
sns.despine()
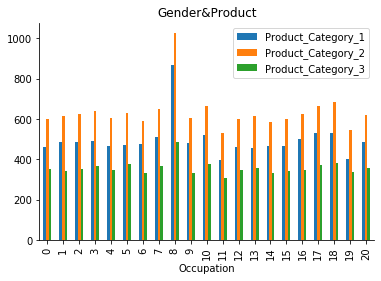
data.groupby(["Occupation"]).mean()[["Product_Category_1", "Product_Category_2", "Product_Category_3"]].plot.bar(title="Occupation&Product")
sns.despine()
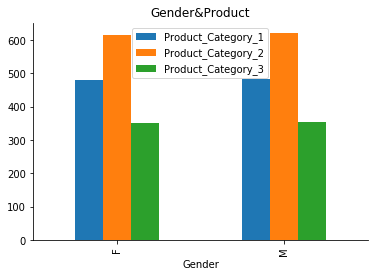
data.groupby(["Gender"]).mean()[["Product_Category_1", "Product_Category_2", "Product_Category_3"]].plot.bar(title="Gender&Product")
sns.despine()
data.groupby(["City_Category"]).mean()[["Product_Category_1", "Product_Category_2", "Product_Category_3"]].plot.bar(title="City_Category&Product")
sns.despine()
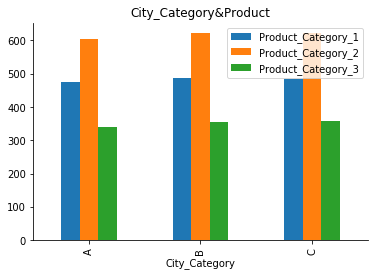
12. Interpretation
Les produits de la catégorie 2 sont nos articles les plus populaires, et cela est vrai pour toutes sortes de clients venant d’horizons différents, ainsi que pour tous les sexes et les types de city.
Analyse prédictive des ventes
1. Corrélogramme
Nous transformons dans un premier temps les variables catégorielles en numerique.
# label encoding: categorical to numeric
le = preprocessing.LabelEncoder()
cat_col = data.select_dtypes(include="object").columns.tolist()
for i in cat_col:
data.loc[:, i] = le.fit_transform(data.loc[:, i])
fig, ax = plt.subplots(figsize=(15, 12))
sns.heatmap(data.drop("User_ID", axis=1).corr(), annot=True, cmap="YlGnBu").set_title("Correlation entre les variables")
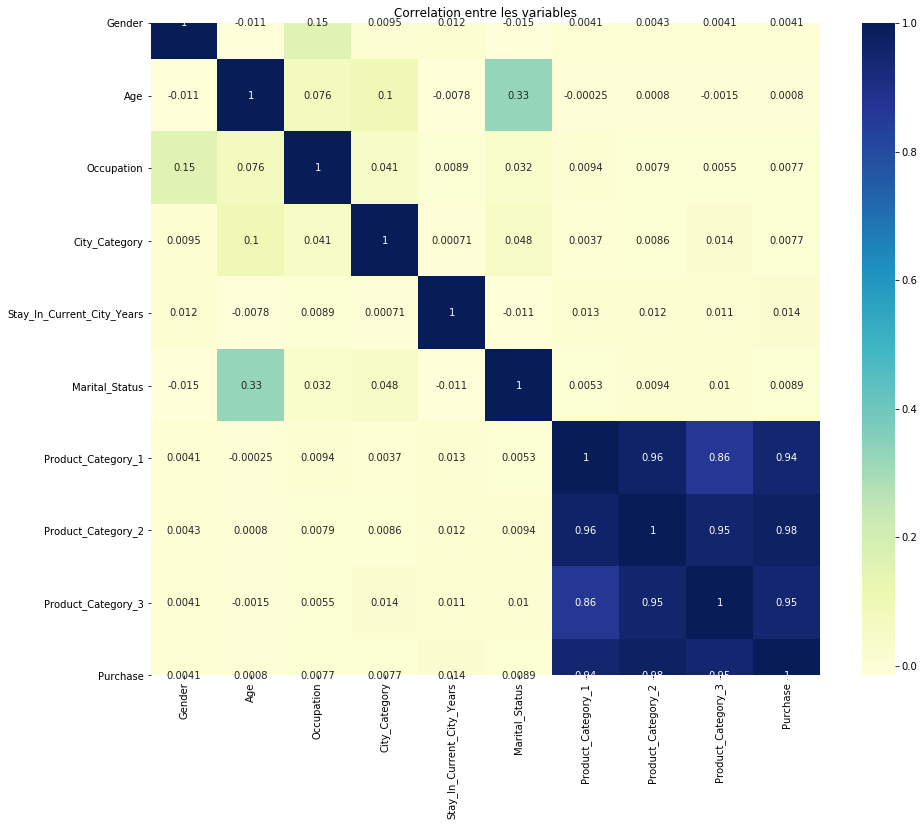
From the heatmap above we can observe there are strong correlations between different types’ products and purchase. There is also some correlation between age and marital status which is in line with common sense. Unfortunately, there is no single feature that shows strong correlation with purchase directly, so we can understand this as that purchase depends on the ensemble of all features.
2. Interpretation
À partir de la matrice de corrélation ci-dessus, nous pouvons observer qu’il existe de fortes corrélations entre les produits et les achats (Purchase). Il existe également une corrélation entre l’âge et l’état matrimonial, ce qui est conforme au bon sens.
3. Modèl de prediction par Random Forest
predictor = data.drop("Purchase", axis=1)
target = data["Purchase"]
# Recherche du meilleur parametre par cross-validation
param_grid = {"n_estimators":[1, 5, 10, 50, 100, 150, 300, 500], \
"max_depth":[1, 3, 5, 7, 9]}
grid_rf = GridSearchCV(RandomForestRegressor(), param_grid, cv=5, scoring="neg_mean_squared_error").fit(predictor, target)
print("Best parameter: {}".format(grid_rf.best_params_))
print("Best score: {:.2f}".format((-1*grid_rf.best_score_)**0.5))
Best parameter: {'max_depth': 9, 'n_estimators': 100}
Best score: 192178.99
4. Construction du modèl avec les bons paramètres
# make model with best parameters
model = RandomForestRegressor(n_estimators=500, max_depth=9, random_state=1, verbose=1)
# predict with cross validation
scores = cross_val_score(model, predictor, target, scoring="explained_variance", cv=5)
print(scores)
print("Model effectiveness: %f" % (scores.mean()))
