Scraping et visualisation des données Facebook avec R
Published:
Introduction
Dans mon précédant article, j'ai montré combien les réseaux sociaux constituaient une mine d'or de données. Dans ce article, nous allons gratter les données de Facebook avec le package Rfacebook. Ensuite, nous utiliserons ggplot2 pour nos visualisations. Je vais utiliser les données d'un groupe privé que je partageais avec des amis pour publier des liens vers de la musique qui, selon nous, méritaient d'être écoutées, mais cela peut être appliqué à n'importe quelle page Facebook. Particulièrement utile si vous voulez essayer de donner un sens aux données d'un groupe Facebook, ou si vous êtes juste un narcissique enragé et que vous voulez savoir à quelle heure de la journée pour publier votre photo de profil pour avoir le plus de likes.
Data Scraping par API
Nous allons commencer par chargé les packages nécessaire pour le raclage te la visualisation.
library(Rfacebook)
library(tidyverse)
library(forcats)
library(lubridate)
library(hrbrthemes)
library(ggalt)
library(ggbeeswarm)
library(plotly)
Maintenant, pour accéder à l'API Facebook, vous devez vous rendre sur le site des développeurs de Facebook , créer votre propre <<application >>, puis enregistrer le token qu'il vous donne en tant que variable pour faciliter l'utilisation plus tard.
Une fois cela fait, enregistrez votre group_id en tant que variable (normalement c'est un nombre à 15 chiffres qui vient après le nom du groupe dans l'URL du groupe).
NB: vous pouvez également essayer cela avec des pages Facebook publics. Collez simplement l'ID de la page.
token <- 'XXXXXXXXXXXXXXXXXXXXX'group_id <- 'XXXXXXXXXXXXXXXXXX'
Maintenant, construisons une fonction qui fera tout le nécessaire pour nous et produira une trame de données bien rangée avec uniquement les données qui nous intéressent. Dans notre cas, ce sera le titre d'une vidéo youtube qui sera très probablement un titre de chanson. Cela me permet de savoir rapidement quelles chansons ont été publiées dans le groupe sans avoir à suivre chaque URL.
Cela nécessite un peu de travail supplémentaire dans la fonction car la fonction getGroup de Rfacebook ne renvoie pas les titres des liens, seulement les URL. Mais si vous n'avez pas besoin de ces informations, vous pouvez les ignorer et votre vie est beaucoup plus facile.
Les principales modifications que nous allons effectuer sont toutes liées à la date et l'heure. Pour explorer diverses relations entre les publications dans le groupe et l'heure, il est utile d'agréger jusqu'à des catégories de temps plus larges. Facebook nous donne la date et l'heure de chaque publication à la seconde exacte. Nous arrondirons ensuite cette date à la minute, l'heure, le jour de la semaine et le mois.
Voici la fonction de grattage complète. La variable limit permet de définir combien de publications nous voulons récupérer sur les serveurs de Facebook. Sans cela, vous obtenez 25 messages assez pathétiques, mais l'une de mes motivations pour ce faire était d'obtenir un accès instantané aux messages historiques remontant au début du groupe fin 2015 jusqu'à 2017 l'année à laquelle le groupe est resté inactive (parce qu'on devenait plus responsable).
group_scrape <- function(token, group_id, limit) {
#fonction pour traiter les dates
format.facebook.date <- function(datestring) {
date <- as.POSIXct(datestring, format = "%Y-%m-%dT%H:%M:%S+0000", tz = "GMT")
}
#appel de la fonction Rfacebook
data_main <- getGroup(group_id, token, feed = TRUE, n = limit)
#appel de l'API poour obtenir le nom du lien dans toute publication qui en a un
link_names <- callAPI(paste0("https://graph.facebook.com/v2.9/", group_id,
"?fields=feed.limit(", limit, "){name}"), token) #fonction pour extraire les données des listes et les placer dans data_main
link_names <- bind_rows(lapply(link_names$feed$data, as.data.frame))
#Gestion des dates
days <- c("Monday", "Tuesday", "Wednesday", "Thursday", "Friday", "Saturday", "Sunday")
#fusionner les deux jeux de données sur la variable id post
final <- merge(data_main, link_names, by = "id")
#suppression les publications qui ne contiennent pas de lien
final <- final[complete.cases(final[,12]),] %>%
mutate(created_time = format.facebook.date(created_time),
Date = as.Date(created_time, format = "%d/%m/%y"),
Minute = make_datetime(2017, 01, 01, hour(created_time), minute(created_time), 0, tz = "GMT"),
Hour = make_datetime(2017, 01, 01, hour(created_time), 0, 0, tz = "GMT"),
Day = factor(weekdays(created_time), levels = days),
Month = make_date(year(created_time), month(created_time), 01),
Link = paste0("<a href='",link,"' target='_blank'>","open link...","</a>")) %>%
select(Date, Month, `Posted By` = from_name, Track = name, Day, Hour, Minute, Likes = likes_count,
Comments = comments_count, Link)
#suppression des emojis
final$Track <- sapply(final$Track, function(row) iconv(row, "latin1", "ASCII", sub=""))
return(final)
}
Maintenant, appellons la fonction group_scrape avec notre token, group_id et limit=1500 pour les 1500 messages
tunes <- group_scrape(token = token, group_id = group_id, limit = 1500)
Visualisation des données
Je vais explorer quelques relations dans les données à titre d'exemple.
Pour éviter que mes amis et moi-même ne soyons gênés par des choses comme les post-pitoyables: j'aime anonymiser les noms des membres du groupe.
per_month <- count(tunes, 'Posted By', Month) %>%
mutate('Posted By' = 'Posted By' %>% fct_rev())ggplot(per_month, aes(Month, n, group = `Posted By`, fill = `Posted By`)) +
geom_area(alpha = 0.7) +
theme_ipsum_rc(caption_size = 12) +
scale_x_date(date_labels = "%b %Y", date_breaks = "2 months") +
scale_fill_brewer(palette = "Dark2") +
labs(y = "", x = "", title = "Facebook Group", subtitle = "Posts per Month") +
theme(legend.direction = "horizontal", legend.position=c(0.8, 1.05))
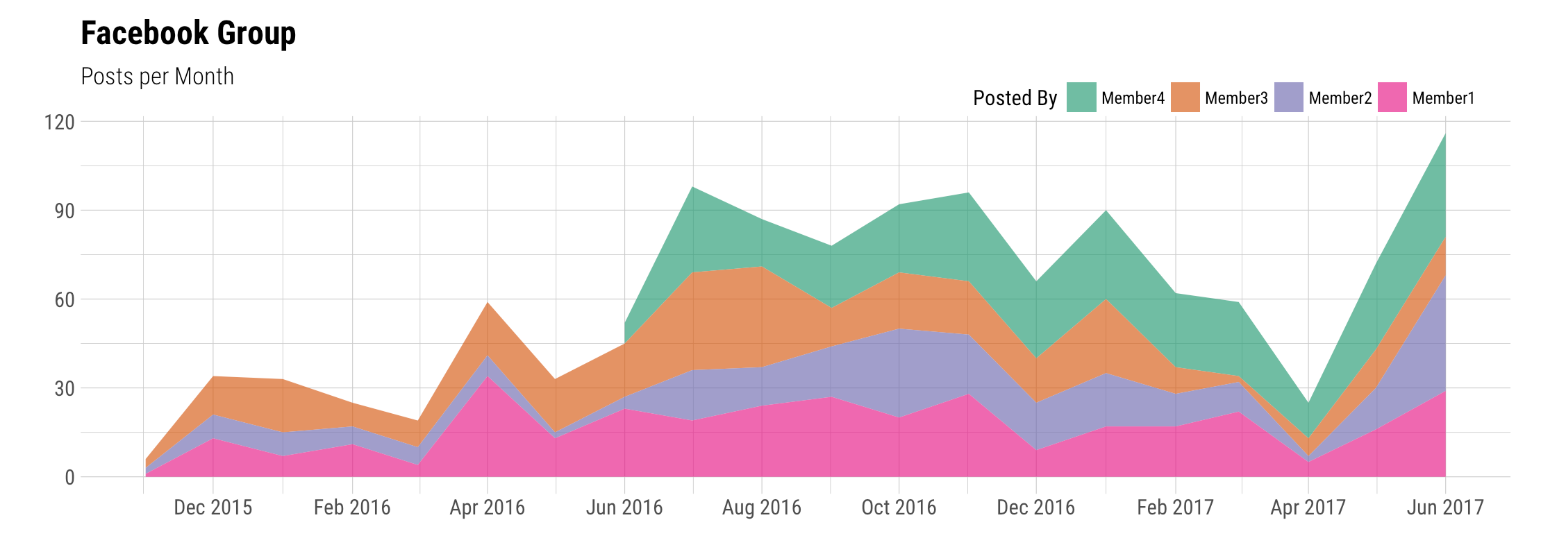
Nous allons maintenant essayer de regarder le message par jour de la semaine puis par heure pour voir s'il y a des variations sensibles.
per_day <- count(tunes, Day) %>%
mutate(Day = Day %>% fct_rev())ggplot(per_day, aes(n, Day)) +
geom_lollipop(point.colour = "SteelBlue", point.size = 4, horizontal = TRUE) +
theme_ipsum_rc(grid = "X", caption_size = 12) +
labs(y = "", x = "", title = "Facebook Group", subtitle = "Posts per Day")
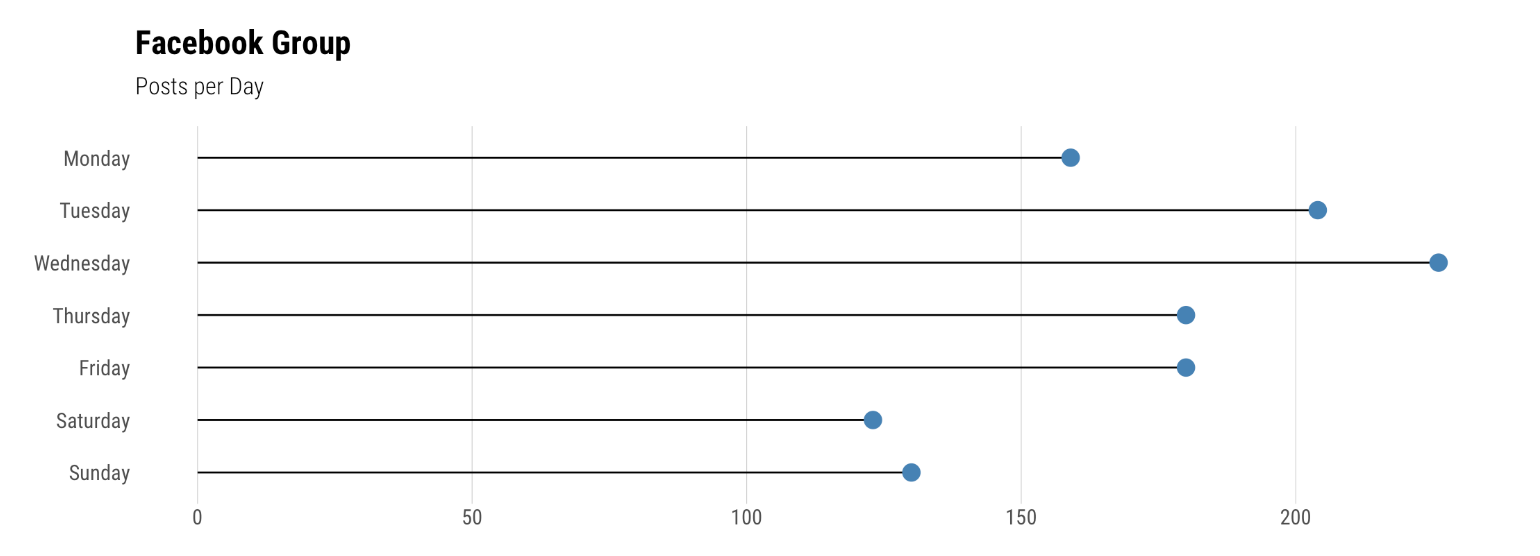
per_hour <- count(tunes, Hour)ggplot(per_hour, aes(Hour, n)) +
geom_bar(stat = "identity", fill = "SteelBlue") +
theme_ipsum_rc(caption_size = 12) +
scale_x_datetime(date_labels = "%H:%M", date_breaks = "2 hours") +
labs(y = "", x = "", title = "Facebook Group", subtitle = "Posts per Hour")
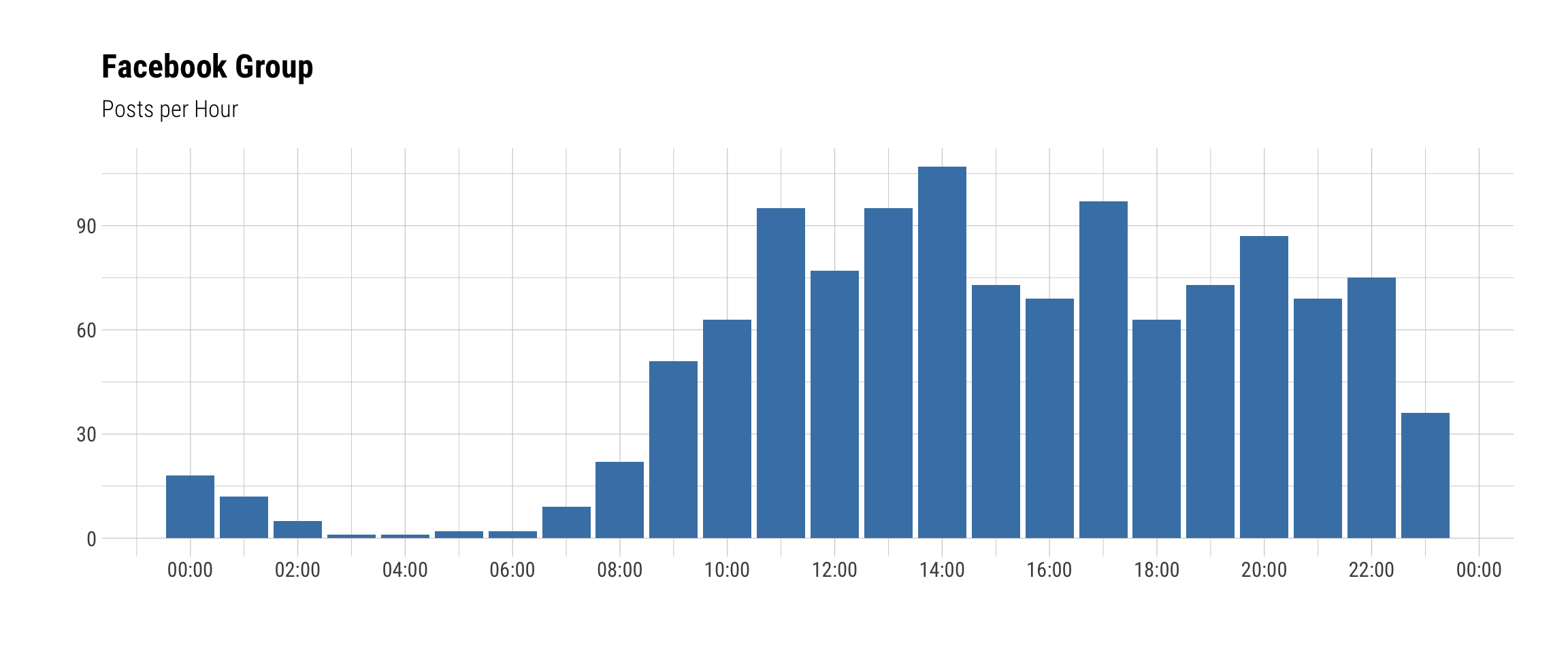
Conclusion
C'est tout pour cet article. Si vous avez des pensées ou des questions ou d'autres idées pour améliorer mes articles, merci de mes les laisse en commentaire.
Et si vous souhaitez donner vie à vos données avec une visualisation sur mesure comme ci-dessus, contactez-moi.
