Système de recommandation avec Python et R
Published:
Introduction
Dans la première partie de cet article, nous nous intéresserons à la partie data collection. Nous verrons comment nous avons récupéré ces données (par scraping), et à quelles données s'intéresser dans un système de recommandation. Dans la seconde partie nous nous intéresserons au fonctionnement théorique et pratique d'un système de recommandation basée sur l’algorithme de similarité. Et enfin, l’intégration et le déploiement de tous ces processus dans notre application movie-space.
Vous pouvez consulter l’application en ligne en suivant ce lien : http://movie-space.ga/ ou https://movie-space.herokuapp.com/. Le projet est également consultable sur mon repertoire Github à travers ce lien : https://github.com/armelsoubeiga/Movie-Space
Collecte de données par Scraping
Nous avons construit une base de données de plus de 1600 films et de plus 2000 séries. Ces données ont été obtenues par le raclage du web. En effet, nous avons récupérer sur le site torrent https://www.torrent9.pl/ (attention c’est un site web reconnu illégalement en France). Bref mais l’objectif c’est de vous montrer comment on peut extraire ce type de données.
Pour scraper un site web sans API, il faut essentiellement definir et comprendre ces trois (3) parties ci-dessous :
- La structure du site web : dans notre cas, on a remarqué que le site est organisé par onglets (onglet des films, onglet des séries, …). Ensuite sur chaque page on a un tableau de 50 films/séries qui s’affichent (en claire les médiats sont affichés par 50 sur chaque page). On a le nom, les nombres d’enregistrement des torrents. On peut également voir que chaque nom constitue un lien qui pointe vers les informations détails de ce media. J’appelle cette partie la conception de l’algorithme de scraping.
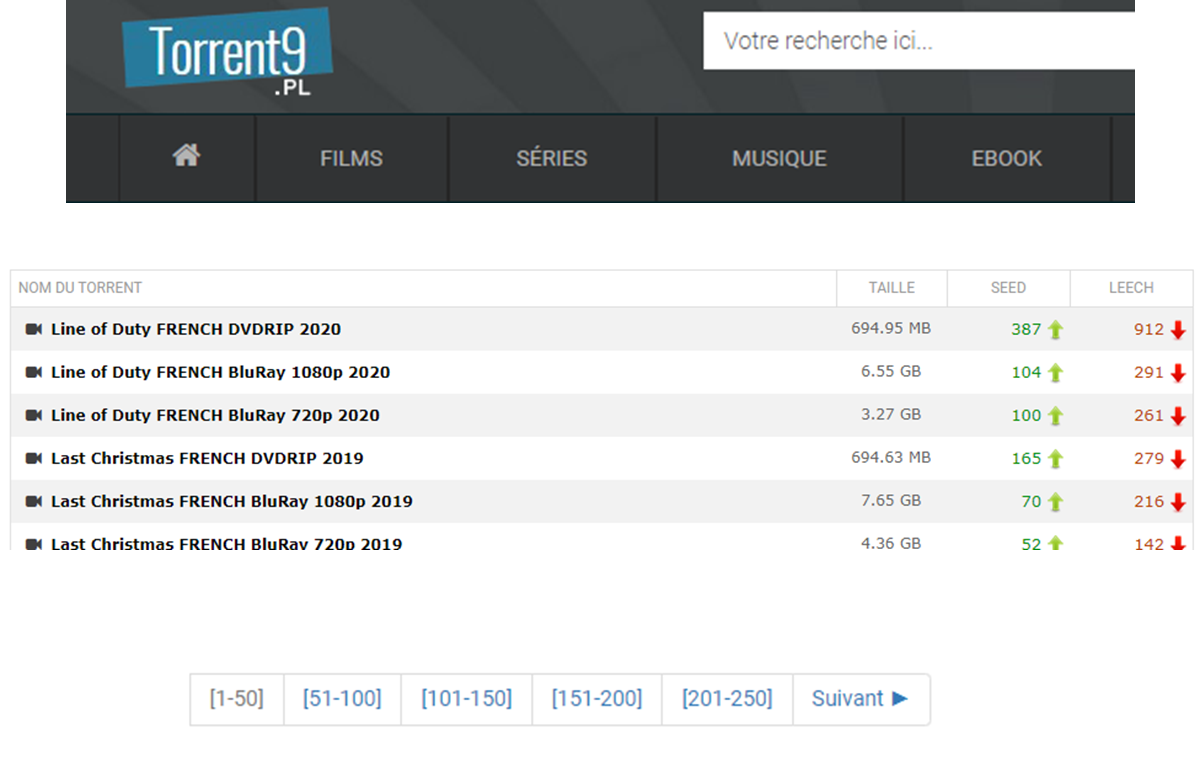
Structure visuelle du site web
- Le développement des différentes fonctions pour accéder et parcourir le schéma défini ci-dessous de façon séparé.
library(rvest)
library(stringr)
library(dplyr)#torrent url
url <-'https://www.torrent9.pl/torrents/films/'#recuperer toutes les pages
all_url <- str_c(url,seq(51,1551,50),sep='')
all_url <- c(url,all_url)Recuperation des lien de toutes les pages des 1600 films
get_url_by_page <- function(html){
url_ <- html %>%
html_nodes('table td a ')%>%
html_attr("href")
url_ <- paste('https://www.torrent9.pl',url_,sep='')
return(url_)
}Récupération des urls (50 films) sur une page
get_data_of_each_page <- function(html){
movie_title <-html %>%
html_nodes('.movie-section .pull-left')%>%
html_text() %>%
str_trim()
movie_category <-html %>%
html_nodes('.movie-information ul>li')%>%
html_text() %>%
str_trim()
a=data.frame(v1 = movie_category) %>%
mutate(v1 = strsplit(as.character(v1), ':'))
b=read.table(text = gsub("\\s", "", a$v1),
strip.white=TRUE, header = FALSE)
b=b[b!='character(0)']
movie_info_ <- as.data.frame(matrix(b, ncol = 6, byrow = FALSE), stringsAsFactors = FALSE)
movie_info <- data.frame(movie_info_[2,])
colnames(movie_info) <- as.character(movie_info_[1,])
movie_description <-html %>%
html_nodes('.movie-information p')%>%
html_text()
movie_description <- movie_description[3]
movie <- cbind.data.frame(movie_title,movie_info,movie_description)
return(movie)
}Récupération des informations de chaque film
- En in l’automatisation de tout le processus en connectant les différentes fonctions programmées.
cbind.fill <- function(...){
nm <- list(...)
nm <- lapply(nm, as.matrix)
n <- max(sapply(nm, nrow))
do.call(cbind, lapply(nm, function (x)
rbind(x, matrix(data = NA, n-nrow(x), ncol(x)))))
}
#Scraping all data
all_movie_data <- data.frame()for(page_url in all_url){ print(page_url)
read_page_url <- read_html(page_url)
liste_page_movie <- get_url_by_page(read_page_url)
page_movie_data <- data.frame()
for(movie_url in liste_page_movie){
print(movie_url)
read_movie_url <- read_html(movie_url)
movie_data <- get_data_of_each_page(read_movie_url)
page_movie_data <- rbind.data.frame(page_movie_data,movie_data)
}
all_movie_data <- rbind.data.frame(all_movie_data,page_movie_data)
}Automatisation de tout le processus
NB: il s’agit d’un cas assez simple de récupération des données. En fonction des besoins cela peut être plus compliqué que ça.
Systèmes de recommandation
« N’écoute pas tes sentiments, écoute l’algorithme, il te connaît mieux. »
Les systèmes de recommandation (SRec) visent à proposer des « articles » (items) à des « utilisateurs » (users). Employés au départ dans le commerce en ligne, leur domaine d’application ne cesse de s’élargir : musique, films, livres, sites web, blogs, destinations de voyages, applications pour mobiles, publications de recherche, etc. Les SRec intègrent des informations de différents types, issues de plusieurs sources, explicites ou implicites : caractéristiques des utilisateurs et des articles, filtrage collaboratif, liens sociaux entre utilisateurs, données issues des capteurs (par ex. GPS), etc.
Il existe plusieurs méthodes et approches de recommandation. Une synthèse assez récente des approches employées pour les SRec en général peut être trouvée dans [BOH13]. Il est également intéressant de lire [BGL15], une synthèse sur les SRec de publications de recherche.
Dans la conception de notre application de recommandation de film et série, nous avons utilisé la méthode de recommandation par similarité de contenu (content-based filtering). Pour cette méthode, un accès aux descriptions des articles est indispensable. Le principe est le suivant : à partir des descriptions des films ou des séries choisis par un utilisateur, sont ensuite proposés à cet utilisateur des films ou séries dont les caractéristiques sont similaires à son choix.
Les variables de descriptions sont diverses. On a les acteurs, les nombres de téléchargements, l’ensemble de mots de description textuelle. Les informations de la catégorie et aux sous-catégories du film ou la série (par ex. le genre d’un film). Ces variables sont ensuite pondérées par des méthodes simples, par ex. term frequency (degré de présence x « potentiel discriminant »).
df = df[['Title', 'Genre', 'Plot']] #'Seed', 'Leech', 'Poidsdutorrent',
df['Genre.plot'] = df['Genre']
df['Plot.plot'] = df['Plot']
df['Plot.plot'].fillna('Sorry ! Pas de descriptions', inplace=True)
df['Genre'] = df['Genre'].map(lambda x: x.lower().split(','))
df['Plot'] = df['Plot'].map(lambda x: str(x).lower().split())
nltk.download("stopwords")
nltk.download('punkt')
df['Key_words'] = ""
for index, row in df.iterrows():
plot = row['Plot']
r = Rake()
r.extract_keywords_from_text(str(plot))
key_words_dict_scores = r.get_word_degrees()
row['Key_words'] = list(key_words_dict_scores.keys())
On applique également une réduction de dimension à la description textuelle (la description des différents films ou série). Cela nous permet de résumer les variables initiales par un plus petit nombre de variables (révéler des « facteurs »), ce qui diminue en général le « bruit » présent dans les descriptions et réduit la gravité de la malédiction de la dimension.
def simila(a,b):
pro =[]
for i in b.index:
seq = difflib.SequenceMatcher(None,a, b[i])
rat= seq.ratio()*100
pro.append(rat)
idx = pro.index(max(pro))
return(idx)
def recommendations(title):
recommended_movies = []
recommended_movies_genre = []
recommended_movies_desc = []
try:
idx = simila(title,indices)
#idx = indices[indices == title].index[0]
except:
res = "This movie in not registered in our database"
genre = 'NaN'
desc = 'NaN'
return res, ['0'], genre, desc
# creating a Series with the similarity scores in descending order
score_series = pd.Series(cosine_sim[idx]).sort_values(ascending=False)
top_3_indexes = list(score_series.iloc[1:4].index)
for i in top_3_indexes:
recommended_movies.append(list(df.index)[i])
recommended_movies_genre.append(df['Genre.plot'][i])
recommended_movies_desc.append(df['Plot.plot'][i])
return recommended_movies, score_series[1:4],recommended_movies_genre, recommended_movies_desc
Déploiement de l’application en ligne
Développement de l’application
Pour le déploiement de notre application de recommandation de film et série, nous avons utilisé le Framework Flask.
![]()
image de flask
Flask est un Framework open-source de développement web en Python. Son but principal est d'être léger, afin de garder la souplesse de la programmation Python, associé à un système de templates. Il est le deuxième le plus répandu et le plus utilisé après Django. A côte de ces deux Framework Web en Python ont également (Pyramid, CherryPy, Twisted, …)
Dans notre application, nous avons deux parties essentielles. La partie UI, développe en html et css qui est l’interface d’utilisateur (font-end). Qui permet de définir les variables d’entrées et de sorties.
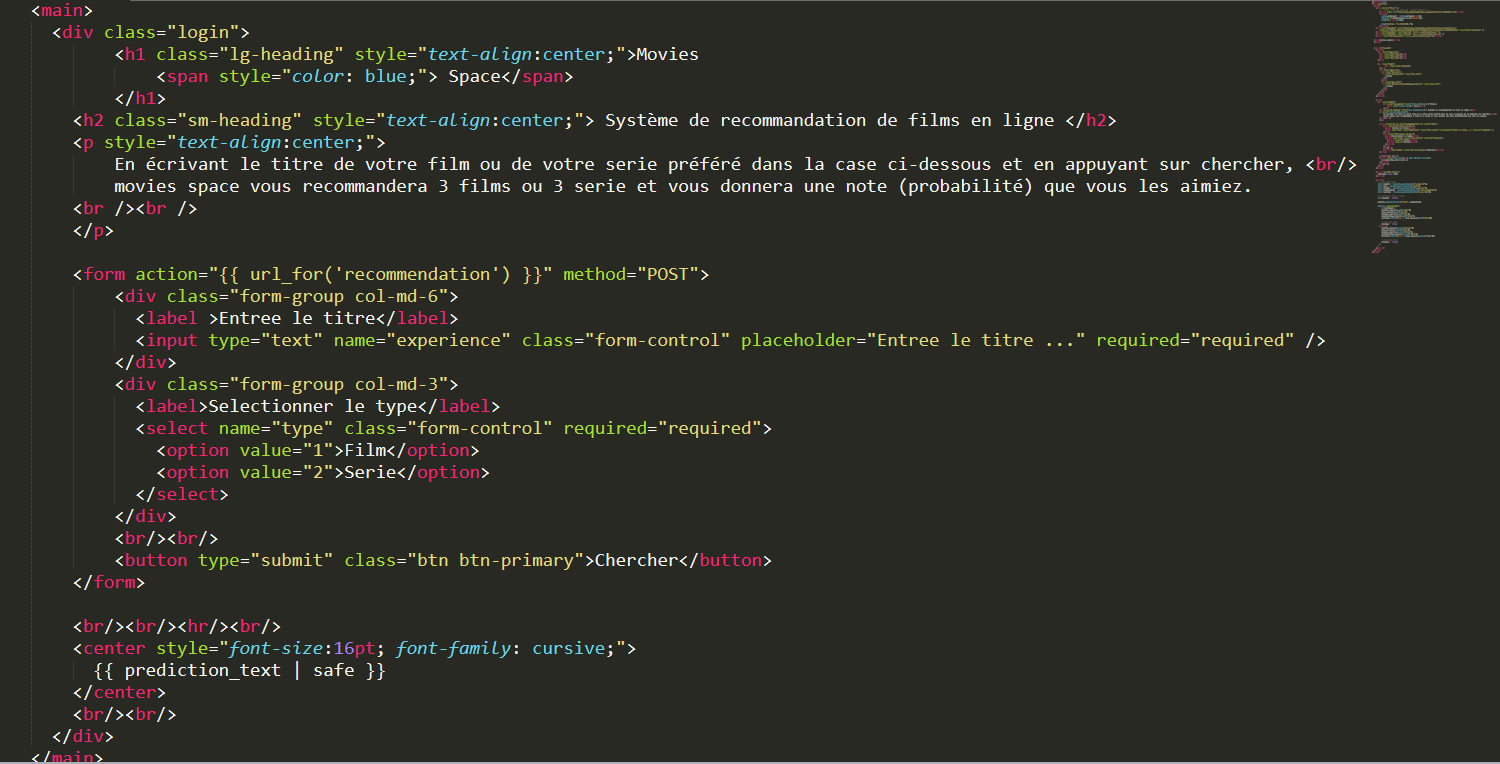
Un extrait de l'UI de l'application
La partie SERVEUR, qui sert de back-end. Elle prend en charge les fonctions python développées pour exécuter les tâches définies plus haut. En effet, les calculs de similarité et de recommandation sont exécutes par python et les résultats sont estitués au UI.
# Rating Page
@app.route("/" , methods=["GET", "POST"])
def rating():
return render_template('welcome.html')# Results Page
@app.route("/recommendation", methods=["GET", "POST"])
def recommendation():
if request.method == 'POST':Un extrait du code de la partie serveur python
Serveur de déploiement

logo heroku
Pour cette application j’ai choisi de la déployer sur HEROKU. Heroku est une entreprise créant des logiciels pour serveur qui permettent le déploiement d'applications web. Créée en 2007, elle est rachetéd en 2010 par l'éditeur Salesforce.com.
Vous pouvez avoir plus d’informations sur ce lien : https://dashboard.heroku.com/
Resource
[BOH13] : Bobadilla, J., F. Ortega, A. Hernando, A. Gutiérez. Recommender systems survey. Knowledge-Based Systems, 46:109–132, July 2013.
[BGL15] : Beel, J., B. Gipp, S. Langer, C. Breitinger. Research-paper recommender systems: a literature survey. International Journal on Digital Libraries, pages 1–34, 2015.
Scikit-learn @ Fondation Inria: https://scikit-learn.fondation-inria.fr/accueil/
